
针对去中心化联邦学习的模型投毒合谋攻击
今天分享人工智能伦理实验室Tis Lab的最新研究Collusive Model Poisoning Attack in Decentralized Federated Learning,本文首次关注了针对去中心化联邦学习的模型投毒攻击,并提出了一种新的合谋攻击方法CMPA,实现对代表性防御方法的有效克服,目前该工作已被IEEE Transactions on Industrial Informatics录用。

智能终端产生的数据呈指数级增长,进而促进了数据驱动的机器学习技术的高质量发展。但传统机器学习借助于集中存储式数据集训练模型,容易存在数据安全及隐私泄露问题,难以满足数据提供者日益严苛的隐私保护需求,甚至与通用数据保护条例(General Data Protection Regulation,GDPR)、健康保险可携性和责任法案(Health Insurance Portability and Accountability Act,HIPPA)等法规相违背。因此以保护数据隐私、提升训练效果为目的的联邦学习(Federated Learning,FL)被提出。作为分布式机器学习的一种代表性范式,FL能够协调多个客户端在遵循“数据不动模型动”的原则下实现联合建模。但传统FL中需要部署中央服务器,负责局部模型的收集、聚合以及全局模型的分发,存在单点故障风险。当FL系统中部署大量客户端或网络带宽较低时,会导致训练效率低下,系统的可扩展性差。为了解决上述问题,不需要中央服务器的去中心化联邦学习(Decentralized Federated Learning,DFL)被提出。在DFL中,所有参与方使用本地数据完成局部模型训练及更新,并借助对等网络与其他参与方交换更新,最终达成模型共识。当通信链路受到高延迟和有限带宽的影响时,DFL被证明比传统集中式FL更有效,并在工业物联网、车联网、无人机网络以及医疗保健系统[等实际场景中得到广泛应用。
作为一种分布式结构系统,FL/DFL中客户端数量众多,给系统的安全性带来了很大威胁。目前已有较多工作关注了FL中的安全问题,提出了多种具备不同威胁模型和目标的投毒攻击。相较于FL,DFL具备去中心化、网络动态性强、参与方间连接性弱、不存在统一的全局模型等特点,为恶意参与方发起投毒攻击提供了更为便利的条件。但是,针对DFL的投毒攻击研究仍然空白。
针对DFL的防御方法
先前的部分工作利用基于统计的稳健梯度聚合规则筛选出异常模型更新。提出了(1)Krum防御方法,其思想是计算参与方局部模型之间的欧几里得距离,并选择与其它模型距离最小的模型作为全局模型,从而排除距离过远的恶意模型更新;(2)基于Median的聚合规则,通过计算局部模型中每个参数维度的中位数作为全局模型参数,从而过滤掉异常模型更新。(3)结合Krum和Median的Bulyan方法。以上这些工作在防御拜占庭攻击方面被证明是有效的,也是目前最为常用的防御方法。
后续的工作为了进一步提升防御效果,探索了基于性能的防御方法。如UBAR首先使用基于距离的方法构建潜在参与方良性参与方候选池,然后借助基于性能的方法从候选池中选择参与方进行模型或梯度更新的参与方。该方法需要额外使用参与方的训练数据来计算模型损失,导致训练过程更为复杂。CAPAR则主要借助于奖励函数和可信度函数对参与方的历史性能进行评估,评估结果决定了参与方的聚合权重,该方法将使得恶意参与方对系统的影响随着权重的变小而减弱,如下图所示,是目前去中心化中最先进的工作。

现有攻击方法的局限性
目前,针对FL的投毒攻击根据攻击者的能力不同可以分为数据及模型投毒攻击,进一步根据目标不同可以分为定向及非定向投毒攻击。定向模型投毒攻击的目的是最小化模型对特定类别测试输入的准确性,同时保持对其它类别预测的高准确性。而非定向模型投毒攻击旨在减少模型对全部测试输入的预测准确率,实现对所有类别的无差别攻击。非定向模型投毒攻击的实施更加便捷,对FL模型整体影响更大,因此受到了更多关注。
但已有的工作往往需要依赖中央服务器获得额外知识(如聚合算法、全局模型等),导致此类工作难以迁移于DFL。此外,DFL去中心化、动态可扩展等特点使得参与方加入/退出训练网络更为便捷、参与方间的沟通十分频繁、模型更新的洪泛式传播也更为迅速,进一步导致针对DFL的攻击方式及效果明显区别于FL。因此,针对DFL的典型特点,展开与模型投毒及合谋攻击相关的研究是十分有价值的。
CMPA:设计和实现
鉴于此,本文发起探讨针对DFL的威胁,并提出了一种模型投毒合谋攻击方法Collusive Model Poisoning Attack (CMPA)。为了使攻击适用于DFL的多种特性,首先设计了一种动态自适应的机制来构建能够有效破坏共识的恶意投毒模型。进一步地,为了增强CMPA的有效性和隐蔽性,设计了基于合谋的攻击增强策略,其中多个恶意参与者协作构建投毒模型,最大化攻击效果以降低共识模型的性能,并交替更新恶意模型以绕过检测的防御方法。如下图所示,恶意对手实施CMPA的流程主要包含以下六个步骤。

其中,动态自适应的恶意模型构造机制由以下算法给出:
以CAPAR为代表的基于性能的防御方法能够根据参与方的长期历史表现评估其可信度,并以此为依据筛选可疑参与方。为了绕过此类防御机制,增强攻击的隐蔽性,本文提出了基于合谋的攻击增强策略,多个恶意参与方在DFL训练过程中的不同轮次交替发送投毒模型,如算法3所示。由于恶意参与方长期处于隐蔽状态,并通过发送正常更新获得高的可信度,使得其间歇性攻击更易成功,并在增强模型投毒攻击的隐蔽性、延长DFL训练时间、降低模型准确率等方面取得了较好效果。
本文借助于图像分类任务验证CMPA的有效性,所使用的基准数据集为MNIST和CIFAR-10,将提出的CMPA与其它3种攻击方法做了对比,并在5种典型防御方法下进一步评估了攻击效果。实验结果如下表所示,在CNN和2NN模型上进行了大量实验,验证了不同攻击方法对训练结果的影响。
在5种防御方法下验证CMPA有效性如下图所示。实验表明,CMPA能够绕开先进的防御机制,并且显著优于其他攻击方法。具体而言,当DFL系统中具有30%的恶意参与方时,5种防御方法都能够很好的抵御甚至完全消除其它3种攻击造成的影响,但却无法有效应对CMPA。此外,即使系统中恶意参与方的占比降为20%,CMPA同样能够实现较强的攻击效果。
评估:实际IIoT场景验证
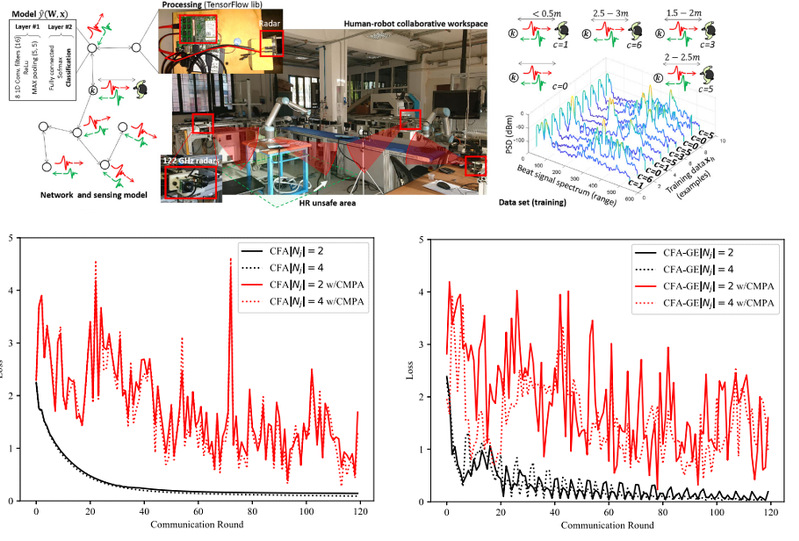
为了证明本文攻击的实际应用价值,我们在真实的工业物联网(Industrial Internet of Things,IIoT)场景中也进行了验证。将攻击应用至IIoT环境中的人机协作任务(HRC)。参考场景是通过D2D自发连接的IIoT设备组成的大规模密集网络。从下图可以看出,无攻击情况下模型在50-60轮后收敛,而当攻击发生时,损失值强烈震荡,导致了对训练任务极大的损害和对共识速度严重的延迟。
结语
这篇论文提出了CMPA,是第一个专为DFL设计的模型中毒攻击。CMPA采用动态自适应机制和基于合谋的攻击增强策略,在隐秘性、持久性和影响力方面表现出色,具有有效攻击IIoT系统的潜力。我们对这项研究的愿望是激发对更多有关DFL攻防的进一步探索。
该研究工作得到了国家自然科学基金重点项目(U22A2099, 62336003)等的支持。
文章链接:https://ieeexplore.ieee.org/abstract/document/10374440
